1. Online information is carefully managed
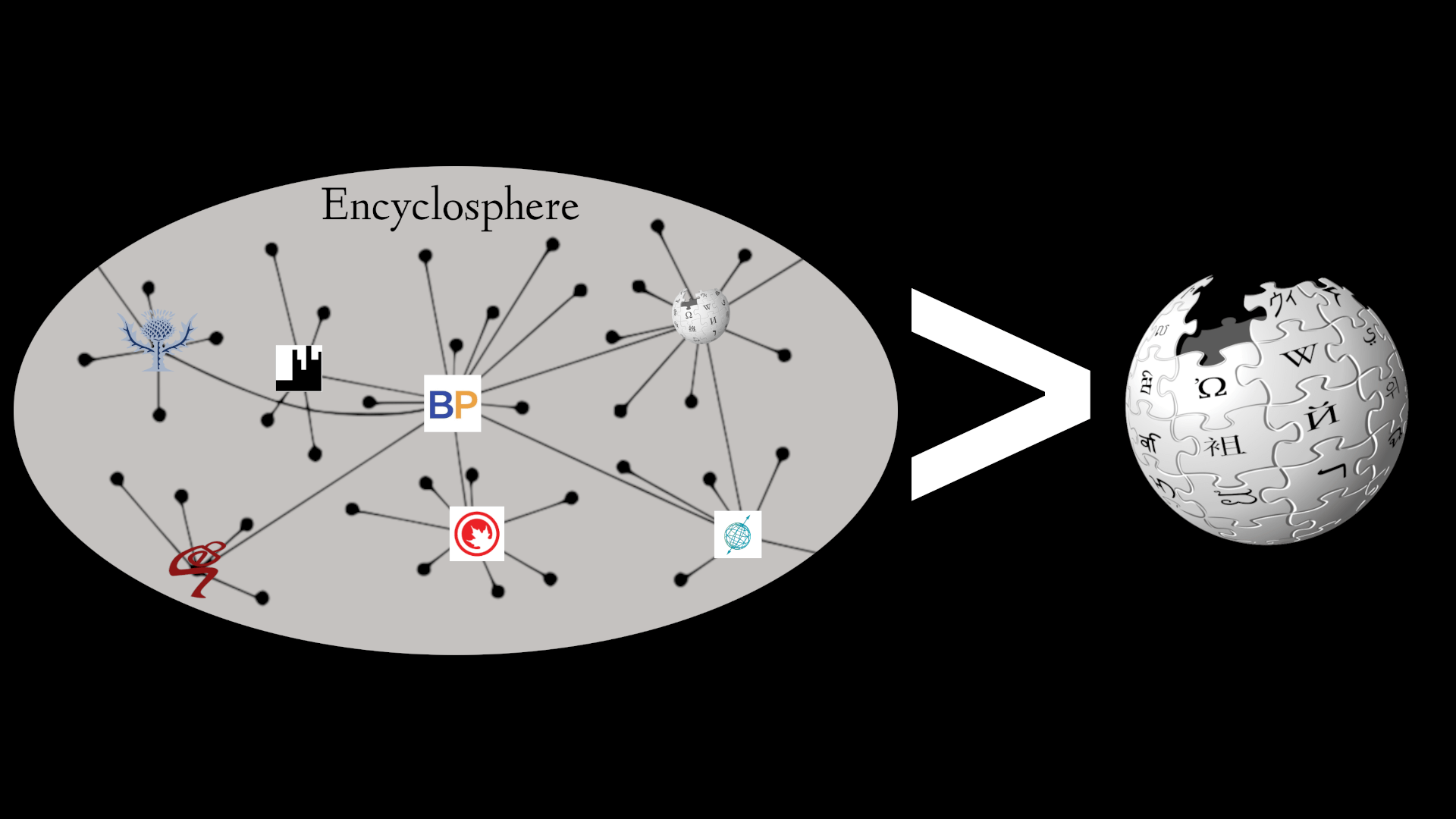
Wikipedia is just one encyclopedia, a ridiculously biased one. The collection of all the encyclopedias—that is what I mean by “the encyclosphere”—is more wide-ranging, fairer, and much larger. It contains sometimes surprising and, in 2023, delightful variety. Articles in other sources are frequently much more credible than those in Wikipedia. Limiting yourself to Wikipedia is like limiting yourself to just the mainstream media sources for your news. Why would you do that to yourself?
There is a problem, however. How can you find all those other articles?
Just Google it? That doesn’t work. Search engines don’t make it easy to discover what is in the encyclosphere. Sure, if you search Google, then you’ll be shown Britannica (typically after Wikipedia) and maybe one or two other mainstream sources like the History Channel or National Geographic. You will be none the wiser about the long tail of free articles online from the many alternative sources. Some of those sources are buried very deep indeed, and in fact might not appear at all for the searches you use. Some articles might as well not exist, as far as most search engines are concerned.
It’s worse than that. As many people have noticed in recent years, Google (and search results generally) have been getting worse, leading one blogger to claim, “Google Search Is Dying.”

That blogger is not wrong. Google is manipulating us, both by showing us mainstream Establishment sources and by effectively omitting large chunks of the internet. It’s getting to the point where it’s often actually faster to find information to go to certain websites and search there.
You might remember the days when Wikipedia was one of those websites we might search directly on. But Wikipedia, even if it is still huge and useful for some topics, is no longer reliable (psst…it never really was). Some of us simply refuse to use it:
Leaping into the breach are AI chatbots, which supply…answers. They are given to bullshitting (“hallucination,” AI experts call it, to make it sound cool) a good 20% of the time, by my completely unscientific estimate. They will get better, however—count on that. The chatbots could, but they do not, give quotations from real human beings; ever wonder why? They do often give you the names and descriptions of things to search for in a more traditional search; they also give you facts to check, and it can be easier to check the accuracy of an alleged fact than it can be to find an answer to a question in a wall of text. So that does help, for sure. AI is very impressive indeed.
But another major problem with AI is that they have been programmed to manipulate your opinions in much the same way that Wikipedia and mainstream media sources do. This is quite deliberate, I think, considering that Google, Wikipedia, YouTube and Twitter algorithms, etc., are deliberatively manipulative. So we can’t expect the problem to go away. Your overlords are pouring billions into AI in no small part because of how rich the opportunities are for using it to control how you think.
You don’t like that, do you?
I absolutely loathe it. It’s an epistemic catastrophe—a massive problem. Nothing less than our freedom and the truth are at stake.
2. We need truly decentralized free content networks
Here’s what we need, as it seems to me:
- We need to make it much easier to find alternative answers to questions, written by human beings, from a wide variety of points of view.
- Considering how eager Big Tech is to censor and control us, we need a fully distributed and decentralized network of free content.
- We need to motivate more experts to share their knowledge more freely online, as they would have been empowered to do if Wikipedia had been governed competently. The more, the better. We don’t want just one supposedly authoritative article on each subject.
- In addition to a traditional search, an AI front end (such as mentioned here) for those texts would be nice to have. In other words, the AI would be a sort of majordomo or concierge representing, specifically quoting, and linking to the answers found in human-written sources.
Let me flesh this out with a picture of what a world of free (or freer) information would look like.
Imagine all the free encyclopedias in a single free database. Not just Wikipedia, but Ballotpedia, Conservapedia, and so forth. Add all the free-to-read but proprietary encyclopedias (like Stanford Encyclopedia of Philosophy), not the articles themselves since that would be illegal, but the titles, URLs, and a description of each article. So now we’re adding things like the many national and state encyclopedias, and specialized encyclopedias about different branches of knowledge. Also, don’t think just English. We do that for all the encyclopedias in every language on the internet. And don’t think just the wikis. Think of every informational website of every kind, as long as they have paragraphs of descriptions of general topics of all sorts. Think also of public domain paper encyclopedias, digitized.
Got that picture? The database would be huge. It would have many more articles than are in Wikipedia.
Next, imagine that we create a common file format for encyclopedia articles. The common format makes it easy for us to share, store, search, and read the articles. The articles are digitally signed, which means you can prove that the articles originated where they are supposed to have originated.
Imagine that all those encyclopedias (or, at least, metadata about the articles) are in a decentralized database. That means there are multiple copies of the entire database located around the internet. Anyone can make a mirror, called an aggregator, complete or partial. Anyone can download articles from any aggregator, and they’re just as good as any copy.
Imagine that anyone knowledgeable about some topic could write an article and add it to this database directly, right from their own blog, wiki, or other sort of website. Now, they would have to package up their article in the encyclopedia format, digitally sign it, and submit it to an aggregator. But imagine there is some software to make that automatic and easy.
In fact, imagine all the software that runs this system is free and open source.
Finally, imagine that there are lots of front ends for this database—websites and apps—where you can search and read all those encyclopedia articles from one place.
This would harden free knowledge against attacks. No longer will authoritarian regimes and corporate arms be able to hide, suppress, restrict, control, and remove it from the internet. Free knowledge will be everywhere in multiple copies. This would be a truly decentralized content network. It would preserve humanity’s knowledge.
3. The encyclosphere: about 50% complete

This picture is what is guiding the Knowledge Standards Foundation, the 501(c)(3) I started in 2019 to make this dream into a reality. The overall project is about 50% finished:
- The free and open Encyclosphere database has over 1.5 million articles from 35 encyclopedias in our database (and counting). When the job is done, we’ll have tens or hundreds of millions of articles drawn from hundreds or thousands of encyclopedias.
- The file format is ZWI. The specification is here.
- The free, open, and self-hosted digital identity standard we follow is DID:PSQR. Documentation here.
- There are encyclosphere aggregators under steady and substantial development: EncycloReader, EncycloSearch, DARA Encyclopedia Archives, and Oldpedia, and another one is going to be launched soon.
- The WordPress plugin that will let you push your posts to the encyclosphere, EncycloShare, is going to be available soon on the WordPress Directory.
- Plugins that push wiki pages to the encyclosphere are available for MediaWiki and DokuWiki.
- Anyone can create their own aggregator. EncycloEngine is 100% open source.
- Our other software is all open to view and use here, on Gitlab.
This is not everything we have done. Though we have made a lot of progress, we still have quite a bit to do. We are going to include ultimately hundreds more encyclopedias and many millions more articles. We will develop more relationships with independent organizations who are developing their own aggregators. In short, we will help humanity to collect all the free encyclopedic knowledge online available into multiple copies.
The result will be much stronger and freer than Wikipedia alone.
We could use your help, especially with funding, but also with coding and ideas. Be sure to follow our Twitter account and to sign up for our newsletter. We’d love to talk to interested philanthropists, publishers, and developers.

Reply to “The Encyclosphere Is Greater than Wikipedia”